

We shall discuss matters pertaining to robot.txt in this blog. What exactly does “robot.txt file” mean?
Why the robot.txt file matters from an SEO standpoint. What are the best practices to follow when constructing it, too?
Lets cover each part one by one.
What do you mean by Robot.txt?
Robot.txt is a file that informs search engines which pages it can crawl and which it cannot crawl.
Robot.txt requests are recognized and honored by all of the main search engines (Google, Bing, and Yahoo).
Why is the Robot.txt file important?
A robots.txt file is not typically required for websites.
That’s because Google can typically identify and index all of your website’s key pages.
Also, they will automatically omit duplicate or unimportant pages from their indexing.
That said, there are 3 main reasons that you’d want to use a robots.txt file:
Block Private Pages: Occasionally, you may have pages on your site that you don’t want search engines to index. You might have a staging version of a page, for instance. Perhaps a login page. These pages are essential. Yet, you don’t want uninvited guests to land on them. In this situation, you would use robots.txt to prevent bots and search engine crawlers from accessing certain pages.
Improve Crawl Budget: You may have a crawl budget issue if you’re having trouble getting all of your pages indexed. Googlebot can focus more of your crawl budget on the pages that are genuinely relevant by blocking unimportant pages with robots.txt.
Prevent indexing of images and pdf: Having a robot.txt file is helpful if you have any images or PDFs on your website that you don’t want search engines to crawl.
How to check if all important pages are indexed?
We can use Google search console to check how many pages are indexed.
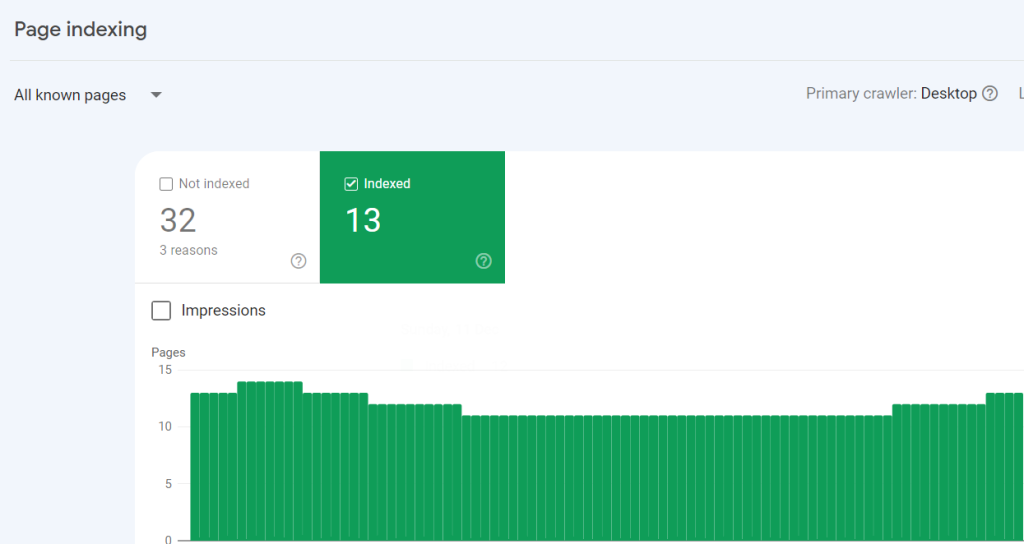
If the number matches with the number of pages you want to be indexed, then you don’t need to worry about the robot.txt file.
But if you notice that number is mismatching, (few URLs not indexed or indexed URL which has to be excluded), then its important to create a robot.txt file for your website.
What is the syntax of the robot.txt file?
Here’s the basic syntax of robot.txt file:
Sitemap: [URL of the sitemap location]
User-agent: [bot-identifier]
[directive 1]
[directive 2]
.
.
[directive n]
This could appear intimidating if you’ve never seen one of these files before. Nonetheless, the syntax is really straightforward.
Simply put, you tell bots what user-agent to use before giving them instructions.
Lets learn more about these two components[User agents & directives] in detail:
User Agents
Each search engine uses a unique user-agent to identify itself. With your robots.txt file, you can include unique instructions for each of these.
There are countless user-agents, but the following few are important for SEO:
- Google: Google bot
- Google images: Googlebot-images
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
To assign directives to all user agents, we can use (*).
Let’s see some examples now:
Example 1: Consider you want your website to be crawled in google only and be blocked by other search engines:
User Agent: Googlebot
Allow: /
User Agent: *
Disallow: /
Example 2: Consider you want to block contents of particular directory from search engines.
User Agent: *
Disallow: /calendar
Remember that you are free to provide instructions (directives) for as many user-agents as you wish in your robots.txt file. Nonetheless, each time a new user-agent is declared, a blank slate is created. The directives specified for the first user-agent do not apply to the second, third, fourth, and so on if.
The only exception to this rule is when you declare the same user-agent many times, this rule is not applicable. In that situation, all applicable instructions are merged and followed.
Directives
Directives are a set of rules which you want user agents to follow.
Here are the list of directives which are currently supported by Google:
Disallow:
This directive must be used when you don’t want search engines to access pages or files.
For example, if you don’t want all search engines to access privacy page of your website, your robot.txt file will look like this:
User-Agent:*
Disallow: /privacy
Do remember, it is important to specify the path after directive or else bots will ignore it.
Allow:
This directive must be used when you want search engines to access pages or files.
For example: Consider you want search engines to access all the pages in the website.
Your robot.txt file will look like:
User-Agent:*
Allow: /
Note: Even in the allow directive, if we fail to specify the path, the bots will ignore it.
Sitemap:
This directive is used to specify the location of your sitemap to the search engines.
It’s slightly redundant for Google if you’ve already published a sitemap using your Google Search Console account. It does, however, let other search engines know where your sitemap has been added, making it an excellent practice.
Here’s an example using sitemap directive:
Sitemap: www.xyz.com/sitemap.xml
User Agent: *
Allow: /
It’s important to note, you don’t have to repeat the sitemap directive several times for every user-agent, The sitemap directive is applicable to all the directives in the file. So it’s always recommended to add the sitemap directive at the beginning or at the end.
Here’s an example with multiple directives:
Sitemap: www.mydomain.com/sitemap.xml
User Agent: Googlebot
Disallow: /career
User Agent: Bingbot
Disallow: /blog/
How can I find if my website contains a robot.txt file?
To check if your website has an existing robot.txt file, simply type on the search bar domain.com/robot.txt. If the contents of the robot.txt file are loaded, your website has a file.
How to create a new robot.txt file?
It’s simple to make a robots.txt file if you don’t currently have one. Simply open a blank.txt file and start entering instructions.
Keep adding all the instructions you need and once you are done, save the file as robots.txt
Where to add the robot.txt file in the website?
Your robots.txt file should be placed in the root directory of the subdomain it relates to.
Best Practices For Robot.txt
The following best practices should be followed while creating a robot.txt file:
Start each directive (instructions) in a new line
Each instruction should start on a separate line. Search engines will become confused otherwise.
Bad:
User-agent: * Disallow: /blogs / Disallow: /privacy/
Good:
User Agent: *
Disallow: /blogs/
Disallow: /privacy/
Use Wildcards(*) To make instructions simpler
Wildcards (*) can be used to match URL patterns when expressing directives as well as to apply them to all user-agents.
For instance, if you wanted to stop search engines from accessing the URLs for your site’s parameterized product categories, you could lay them out like this:
User-agent: *
Disallow: /products/toys?
Disallow: /products/dress?
Disallow: /products/shoes?
…
Yet, that isn’t particularly effective. It might be preferable to make things simpler by using a wildcard like this:
User-agent: *
Disallow: /products/*?
In the given example, all URLs with question marks in the /product/ subfolder are forbidden from being indexed by search engines. To put it another way, any parameterized URLs for product categories.
Ensure to use each user agent only once
Google doesn’t mind if you use the same user-agent many times. It will merely compile all of the declarations’ rules into one and adhere to them all.
For example, if your robots.txt file had the following user-agents and directives…
User-Agent: Googlebot
Disallow: /blog/
User Agent: Googlebot
Disallow: /careers/
Both these pages will not be crawled by the Google.
But if we disclose the user agent only once, we may simplify this procedure even further. This will clear up confusion and cut down on errors.
User-Agent: Googlebot
Disallow: /blog/
Disallow: /careers/
Use comments to explain Robots.txt file
Comments assist developers—and perhaps even your future self—understand your robots.txt file.
You can add comments to your robots.txt file by using hash (#)
#This instructs all search engine pages to not crawl privacy page.
User-Agent: *
Disallow: /privacy
Anything on lines that begin with a hash is ignored by crawlers.
Create separate robot.txt file for each subdomain
If your main website is abc.com and your blog has separate sub domain blog.abc.com, then both website and blog should have different robot.txt file.
To know more about robot.txt, you can refer to this guide from google.
Comments